
데이터의 중복을 줄이고, 무결성을 향상시키는 정규화
# Normalization 목적
테이블 간의 중복된 데이터를 허용하지 않기 위함
중복된 데이터를 만들지 않으면, 무결성을 유지할 수 있고
데이터베이스의 저장 용량 또한 효율적으로 관리할 수 있음
- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킴
- 무결성을 지키고, 이상 현상을 방지
- 테이블 구성을 논리적이고 직관적으로 할 수 있음
- 데이터베이스 구조 확장에 용이
# 정규화 단계
제 1 정규화 -> 제 2 정규화 -> 제 3 정규화 -> BCNF -> 제 4 정규화 -> 제 5 정규화 ... 의 단계
일반적으로 제 3 정규화 또는 BCNF 까지만 하는 경우가 많음
# 정규화 장점
- 데이터베이스 변경 시 이상 현상을 제거할 수 있음
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 됨
- 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미침 -> 생명 연장
# 정규화 단점
- 릴레이션의 분해로 인한 JOIN 연산 증가
- 질의에 대한 응답 시간 느려짐
- 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미로 일반 속성이 하나의 테이블로 집약 -> 한 테이블의 데이터 용량 최소화
- 따라서 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있음
- 조인이 많이 발생하여 성능 저하가 나타나면 역으로 반정규화 적용 가능
# 1NF, 2NF, 3NF 과정
1. 제 1정규화 1NF
테이블 컬럼이 원자값(하나의 값)을 갖도록 테이블 분리
- 어떤 릴레이션에 속한 모든 도메인이 원자값으로만 되어있어야 함
- 모든 속성에 반복되는 그룹이 나타나지 않음
- 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 함
핵심은 원자값으로 만드는 것
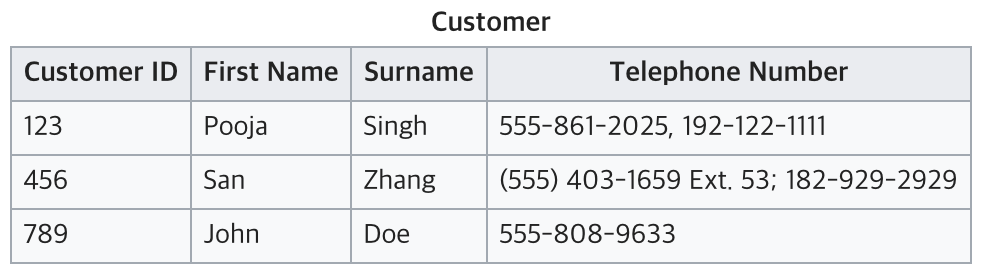
현재 테이블은 전화번호를 여러개 가지고 있어 원자값이 아님
1NF에 맞추기 위해서는 아래와 같이 분리하기
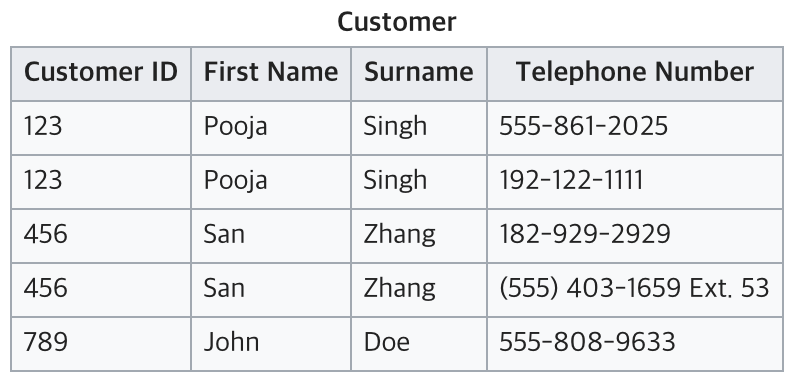
2. 제 2정규화 2NF
테이블의 모든 컬럼이 완전 함수적 종속 만족해야 함
테이블에서 기본키가 복합키(키1, 키2)로 묶여있을 때, 두 키 중 하나의 키만으로 다른 컬럼을 결정 지을 수 있으면 안 됨
기본키의 부분집합 키가 결정자가 되어서는 안 된다는 것
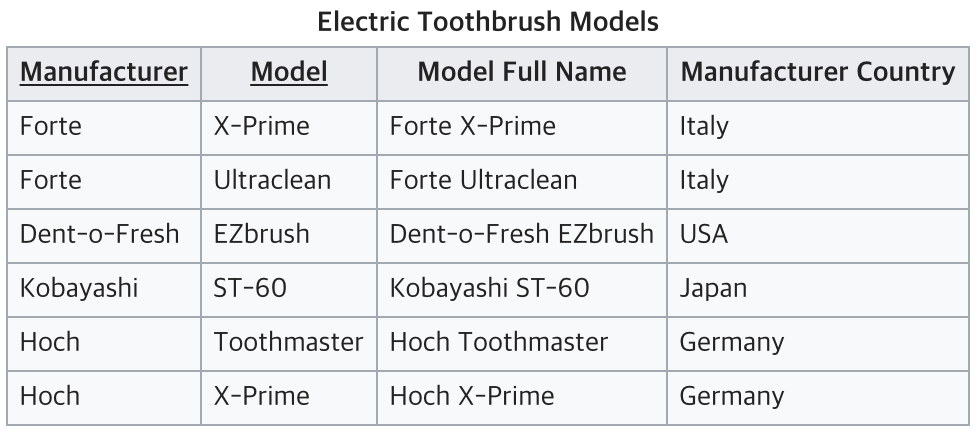
Manufacturer 과 Model 이 키가 되어 Model Ful Name 을 알 수 있음
Manufacturer Country 는 Manufacturer 로 인해 결정됨 (부분 함수 종속)
따라서 Model 과 Manufacturer Country 는 아무런 연관관계가 없음
완전 함수적 종속을 충족시키기 못하는 테이블임
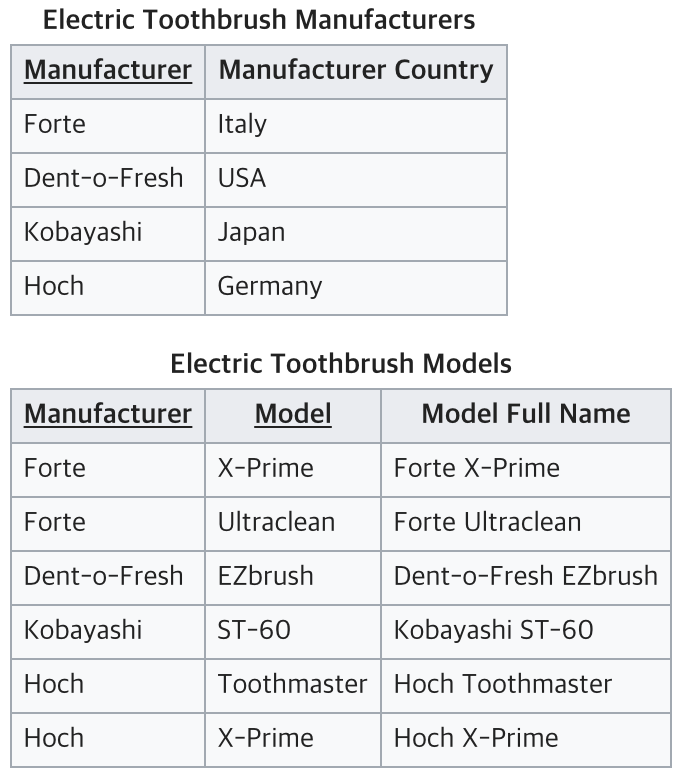
이와 같이 두개의 테이블로 나누면 2NF 충족 가능
3. 제 3정규화 3NF
2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것
# 이행적 종속이란?
A -> B 이고 B -> C 이면 A -> C 가 성립되는 관계
- 릴레이션이 2NF 만족
- 기본키가 아닌 속성들은 기본키에 의존
이 두가지 조건을 만족해야 함
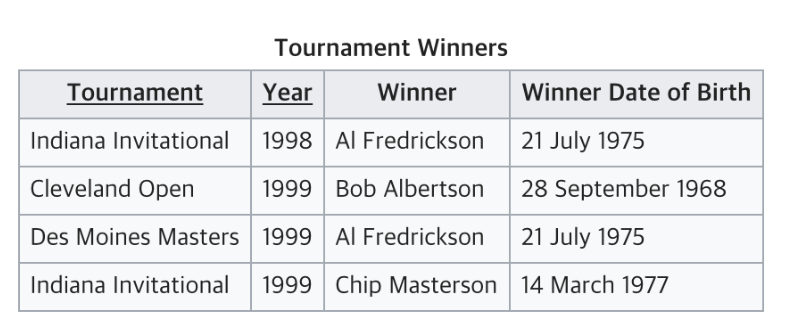
위의 테이블에서 Tournament 와 Year 가 기본키
Winner는 이 두 복합키를 통해 결정됨
하지만 Winner Date of Birth 는 기본키가 아닌 Winner 에 의해 결정
따라서 3NF 위반
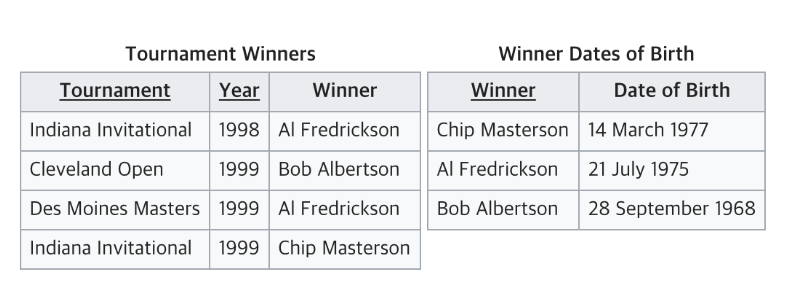
해결 완료!
# 참고
https://gyoogle.dev/blog/computer-science/data-base/Normalization.html
'CS공부 > Database' 카테고리의 다른 글
| Index 인덱스 (1) | 2023.12.08 |
|---|---|
| Anomaly 이상현상 (1) | 2023.12.08 |
| SQL vs. NOSQL (0) | 2023.12.08 |
| SQL Injection (0) | 2023.12.08 |
| Join (0) | 2023.12.08 |
데이터의 중복을 줄이고, 무결성을 향상시키는 정규화
# Normalization 목적
테이블 간의 중복된 데이터를 허용하지 않기 위함
중복된 데이터를 만들지 않으면, 무결성을 유지할 수 있고
데이터베이스의 저장 용량 또한 효율적으로 관리할 수 있음
- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킴
- 무결성을 지키고, 이상 현상을 방지
- 테이블 구성을 논리적이고 직관적으로 할 수 있음
- 데이터베이스 구조 확장에 용이
# 정규화 단계
제 1 정규화 -> 제 2 정규화 -> 제 3 정규화 -> BCNF -> 제 4 정규화 -> 제 5 정규화 ... 의 단계
일반적으로 제 3 정규화 또는 BCNF 까지만 하는 경우가 많음
# 정규화 장점
- 데이터베이스 변경 시 이상 현상을 제거할 수 있음
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 됨
- 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미침 -> 생명 연장
# 정규화 단점
- 릴레이션의 분해로 인한 JOIN 연산 증가
- 질의에 대한 응답 시간 느려짐
- 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미로 일반 속성이 하나의 테이블로 집약 -> 한 테이블의 데이터 용량 최소화
- 따라서 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있음
- 조인이 많이 발생하여 성능 저하가 나타나면 역으로 반정규화 적용 가능
# 1NF, 2NF, 3NF 과정
1. 제 1정규화 1NF
테이블 컬럼이 원자값(하나의 값)을 갖도록 테이블 분리
- 어떤 릴레이션에 속한 모든 도메인이 원자값으로만 되어있어야 함
- 모든 속성에 반복되는 그룹이 나타나지 않음
- 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 함
핵심은 원자값으로 만드는 것
현재 테이블은 전화번호를 여러개 가지고 있어 원자값이 아님
1NF에 맞추기 위해서는 아래와 같이 분리하기
2. 제 2정규화 2NF
테이블의 모든 컬럼이 완전 함수적 종속 만족해야 함
테이블에서 기본키가 복합키(키1, 키2)로 묶여있을 때, 두 키 중 하나의 키만으로 다른 컬럼을 결정 지을 수 있으면 안 됨
기본키의 부분집합 키가 결정자가 되어서는 안 된다는 것
Manufacturer 과 Model 이 키가 되어 Model Ful Name 을 알 수 있음
Manufacturer Country 는 Manufacturer 로 인해 결정됨 (부분 함수 종속)
따라서 Model 과 Manufacturer Country 는 아무런 연관관계가 없음
완전 함수적 종속을 충족시키기 못하는 테이블임
이와 같이 두개의 테이블로 나누면 2NF 충족 가능
3. 제 3정규화 3NF
2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것
# 이행적 종속이란?
A -> B 이고 B -> C 이면 A -> C 가 성립되는 관계
- 릴레이션이 2NF 만족
- 기본키가 아닌 속성들은 기본키에 의존
이 두가지 조건을 만족해야 함
위의 테이블에서 Tournament 와 Year 가 기본키
Winner는 이 두 복합키를 통해 결정됨
하지만 Winner Date of Birth 는 기본키가 아닌 Winner 에 의해 결정
따라서 3NF 위반
해결 완료!
# 참고
https://gyoogle.dev/blog/computer-science/data-base/Normalization.html
'CS공부 > Database' 카테고리의 다른 글
| Index 인덱스 (1) | 2023.12.08 |
|---|---|
| Anomaly 이상현상 (1) | 2023.12.08 |
| SQL vs. NOSQL (0) | 2023.12.08 |
| SQL Injection (0) | 2023.12.08 |
| Join (0) | 2023.12.08 |